FedBPT: Efficient Federated Black-box Prompt Tuning for Large Language Models
Inference is All You Need.
 Best Paper Award in Federated Learning on the Edge, 2024 AAAI Spring Series Symposium
Best Paper Award in Federated Learning on the Edge, 2024 AAAI Spring Series Symposium
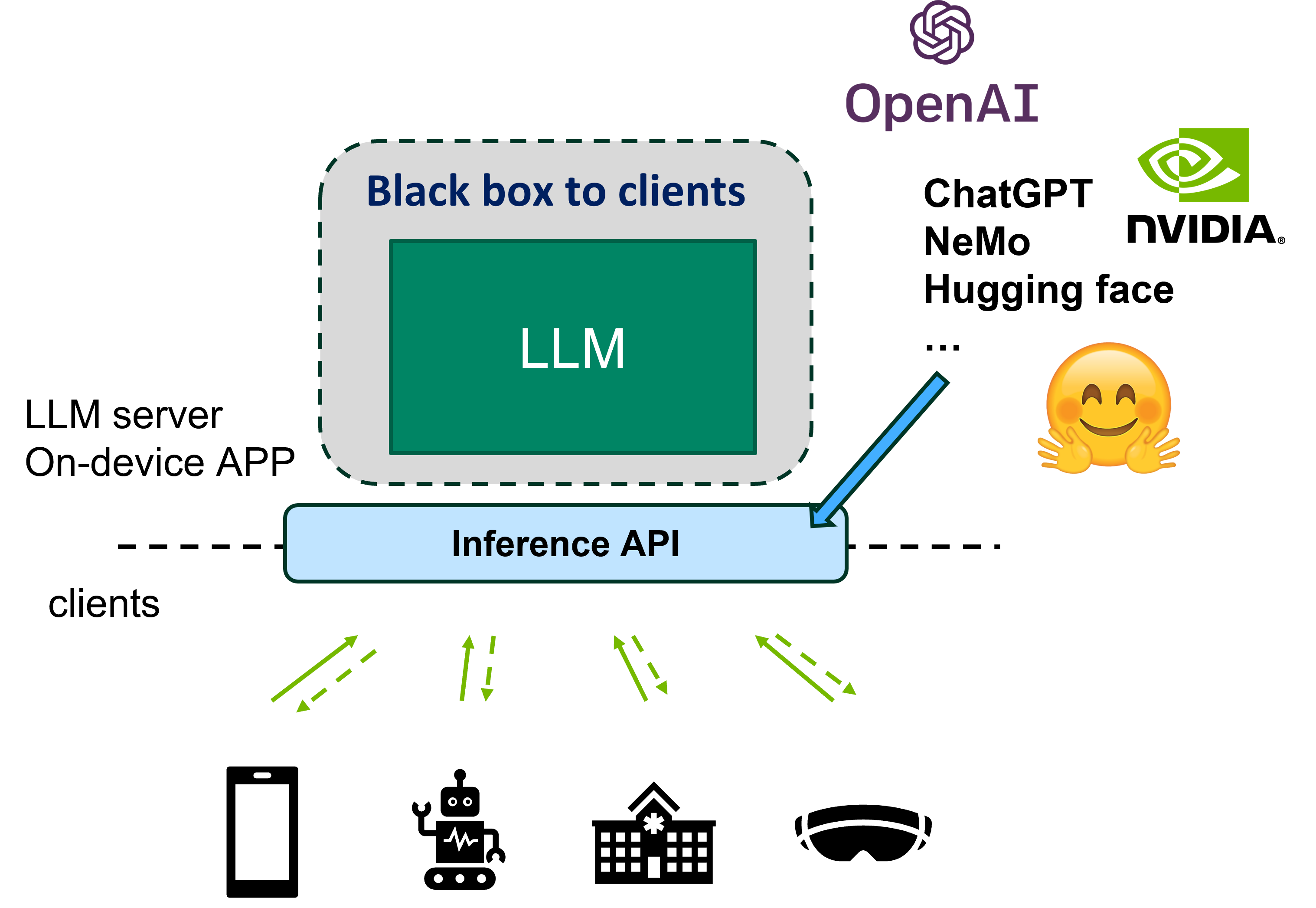
Deploying large language models (LLMs) on edge devices presents several challenges:
- Inaccessible model parameters: Devices typically use LLMs by calling APIs from services like ChatGPT or NeMo. Clients cannot access model parameters directly, preventing them from training the models.
- Resource constraints: Even with access to model parameters, resource-limited devices struggle to perform local fine-tuning of pre-trained language models (PLMs) due to high memory and computational requirements.
- Communication overhead: Fine-tuning PLMs using federated learning (FL) involves frequent exchanges of model parameters or gradients between clients and servers, often in the scale of millions or billions. This intensive communication is impractical for edge devices with limited bandwidth.
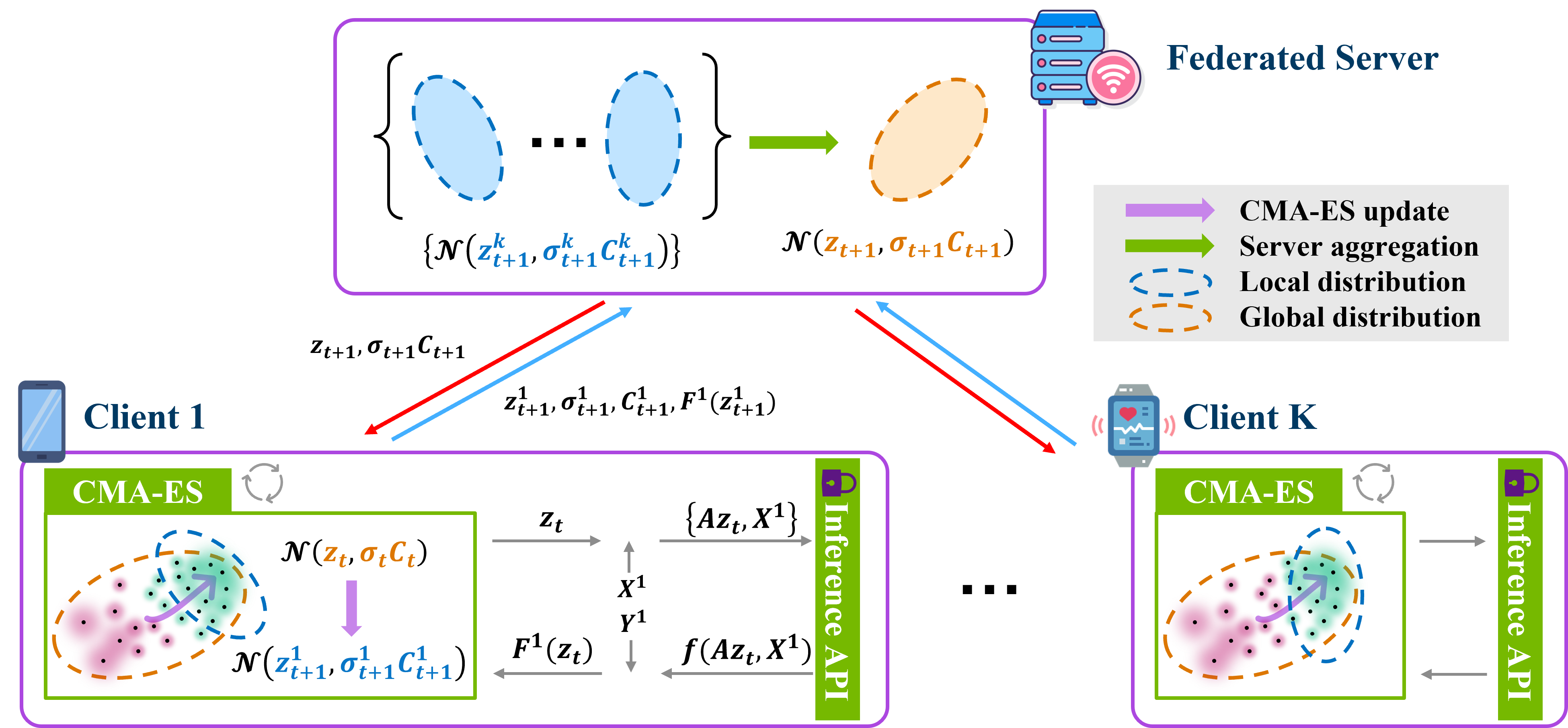
This paper introduces Federated Black-box Prompt Tuning (FedBPT), a framework designed to address these challenges. FedBPT does not require the clients to access the model parameters. By focusing on training optimal prompts and utilizing gradient-free optimization methods, FedBPT reduces the number of exchanged variables, boosts communication efficiency, and minimizes computational and storage costs. Experiments highlight the framework's ability to drastically cut communication and memory costs while maintaining competitive performance. Ultimately, FedBPT presents a promising solution for efficient, privacy-preserving fine-tuning of PLM in the age of large language models.
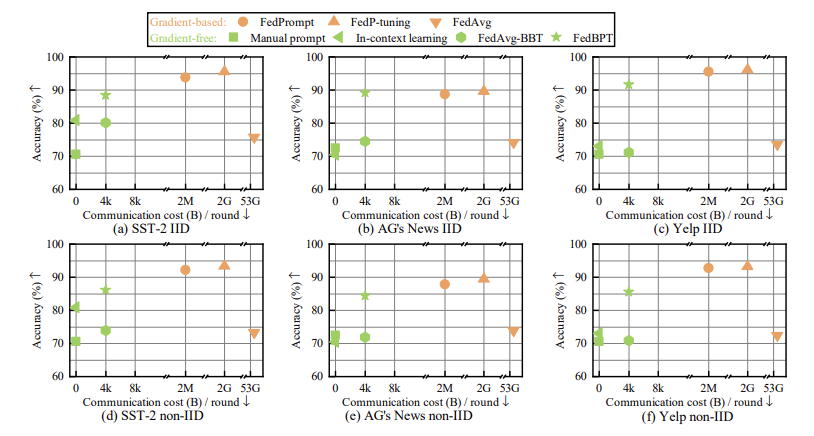
Results on Llama2-7B
Real Device Demo

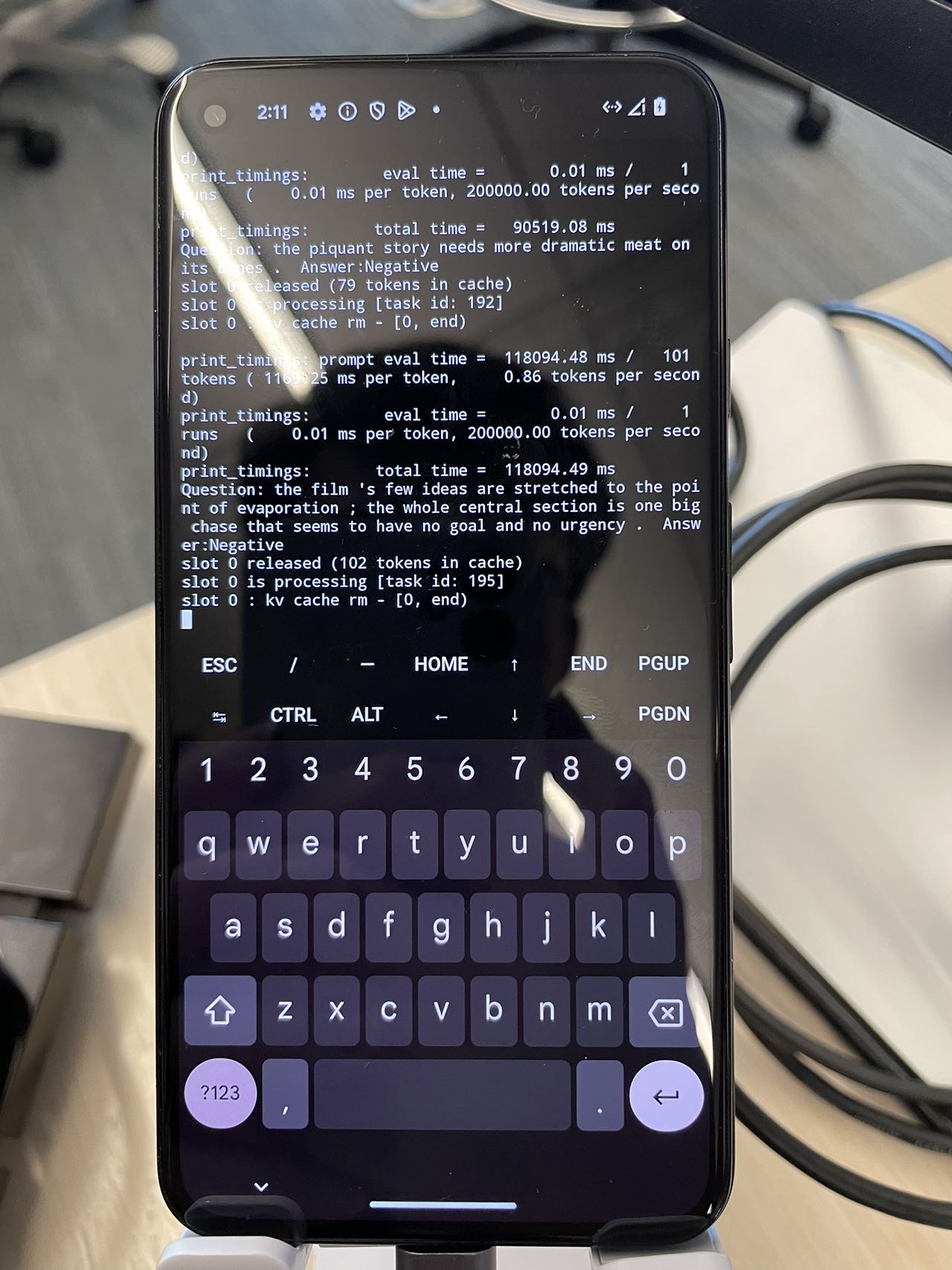
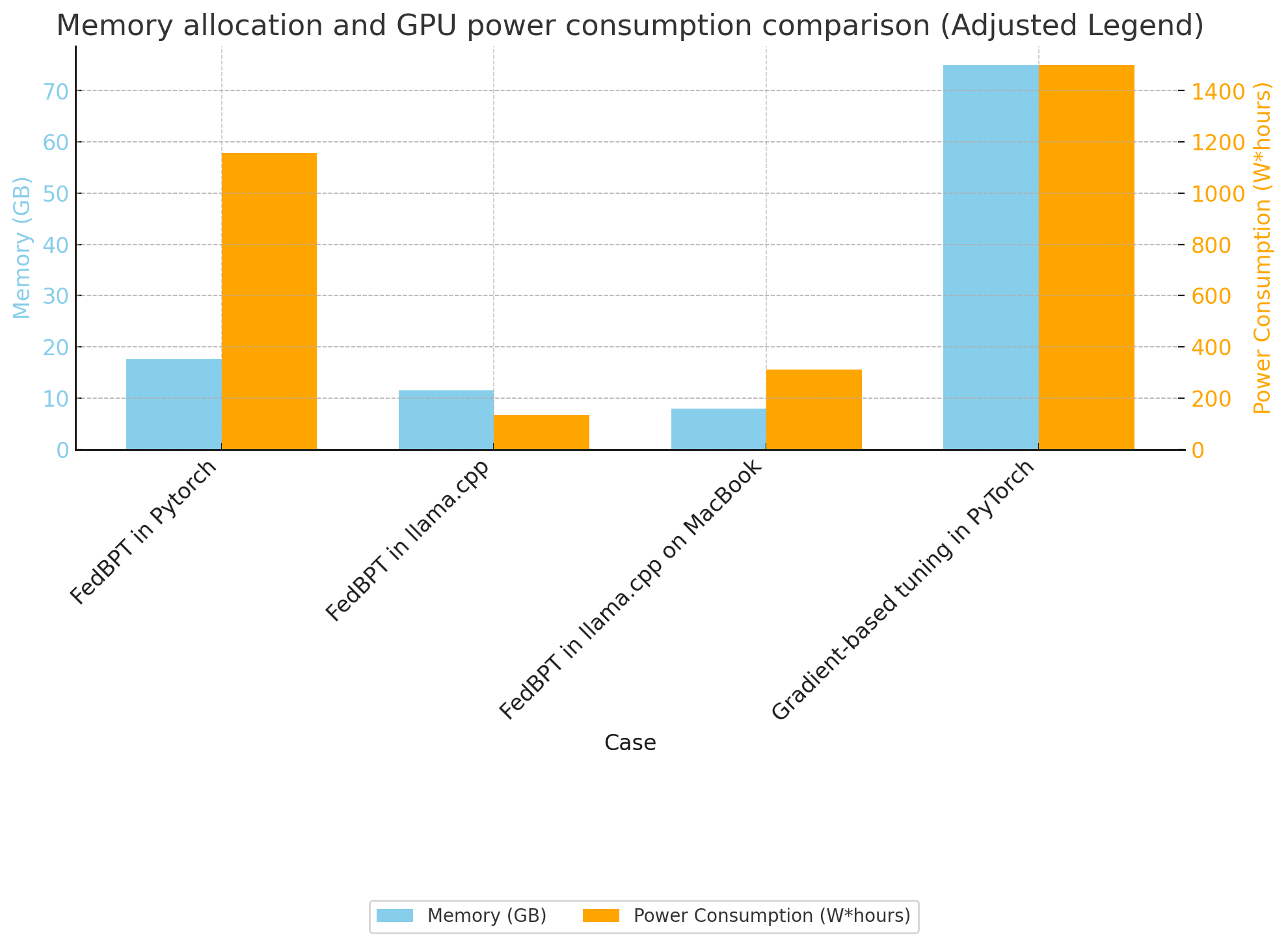
Resource Allocation on Real Devices